代码
# 安装整个tidyverse
install.packages("tidyverse")
# 加载
library(tidyverse)tidyverse生态入门
本讲将介绍R中数据处理与可视化的强大工具——tidyverse:
预计时长:45分钟理论 + 15分钟演示
tidyverse是Hadley Wickham创建的一套统一的数据科学工具包。
| 包名 | 功能 |
|---|---|
| ggplot2 | 数据可视化 |
| dplyr | 数据处理 |
| tidyr | 数据整理 |
| readr | 数据读取 |
| purrr | 函数式编程 |
| tibble | 现代数据框 |
| stringr | 字符串处理 |
| forcats | 因子处理 |
# 安装整个tidyverse
install.packages("tidyverse")
# 加载
library(tidyverse)# 支持图片显示中文字体
showtext::showtext_auto()| 函数 | 作用 | SQL对应 |
|---|---|---|
filter() |
筛选行 | WHERE |
select() |
选择列 | SELECT |
mutate() |
创建/修改列 | 计算字段 |
summarise() |
汇总统计 | 聚合函数 |
arrange() |
排序 | ORDER BY |
library(dplyr)
# 筛选符合条件的数据
iris |>
filter(Species == "setosa", Sepal.Length > 5)# 多条件
iris |>
filter(Species %in% c("setosa", "versicolor"),
Sepal.Length > 5,
Sepal.Width < 4)# 选择指定列
iris |>
select(Sepal.Length, Sepal.Width, Species)# 排除列
iris |>
select(-Petal.Width)# 选择范围
iris |>
select(Sepal.Length:Petal.Width)# 辅助函数
iris |>
select(starts_with("Sepal"))iris |>
select(ends_with("Width"))iris |>
select(contains("Length"))iris |>
mutate(
Sepal.Area = Sepal.Length * Sepal.Width,
Petal.Area = Petal.Length * Petal.Width,
Area.Ratio = Petal.Area / Sepal.Area
)iris |>
summarise(
n = n(),
mean_sepal = mean(Sepal.Length),
sd_sepal = sd(Sepal.Length),
median_petal = median(Petal.Length)
)# 按种类分组统计
iris |>
group_by(Species) |>
summarise(
n = n(),
mean_sepal = mean(Sepal.Length),
sd_sepal = sd(Sepal.Length)
)# 传统写法
result <- summarise(
group_by(
filter(iris, Sepal.Length > 5),
Species
),
mean = mean(Sepal.Length)
)
# 管道写法
result <- iris |>
filter(Sepal.Length > 5) |>
group_by(Species) |>
summarise(mean = mean(Sepal.Length))ggplot2的核心思想:图层叠加
数据 (data) → 映射 (aes) → 几何对象 (geom) → 标度/主题ggplot(data = <DATA>) +
<GEOM_FUNCTION>(
mapping = aes(<MAPPINGS>),
stat = <STAT>,
position = <POSITION>
) +
<COORDINATE_FUNCTION> +
<FACET_FUNCTION> +
<SCALE_FUNCTION> +
<THEME_FUNCTION>| 函数 | 图形类型 |
|---|---|
geom_point() |
散点图 |
geom_line() |
线图 |
geom_bar() |
柱状图 |
geom_histogram() |
直方图 |
geom_boxplot() |
箱线图 |
geom_density() |
密度图 |
geom_smooth() |
平滑曲线 |
library(ggplot2)
# 散点图
ggplot(iris, aes(x = Sepal.Length, y = Sepal.Width, color = Species)) +
geom_point(size = 3, alpha = 0.7) +
geom_smooth(method = "lm", se = FALSE) +
labs(
title = "鸢尾花花萼特征",
x = "花萼长度 (cm)",
y = "花萼宽度 (cm)"
) +
theme_minimal()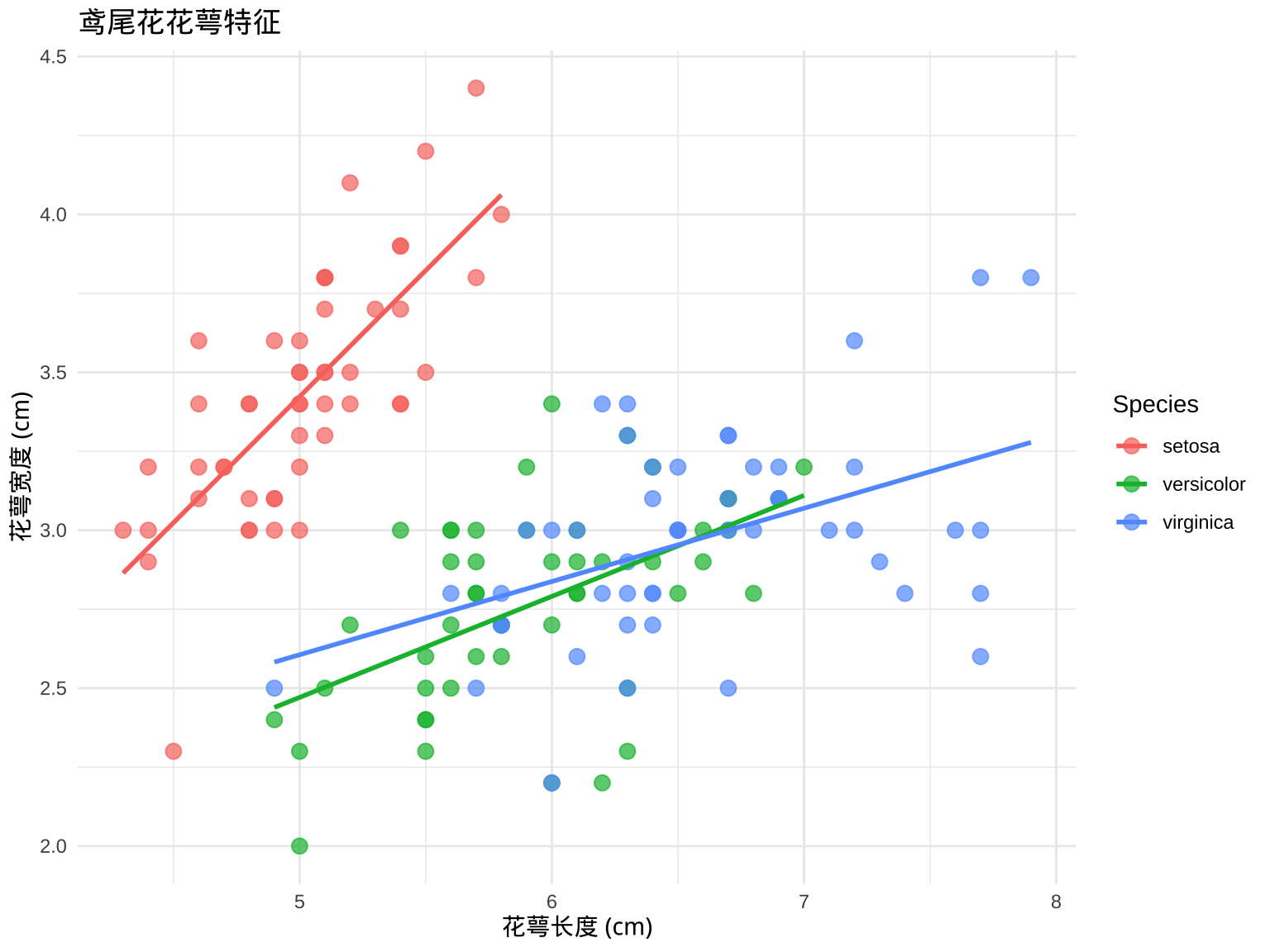
# 加载必要的包
library(readr)
library(dplyr)
library(ggplot2)
# 读取数据
clinical <- read_csv("../data/clinical.csv")
# 数据清洗与分析
clinical_summary <- clinical |>
filter(!is.na(age)) |>
mutate(
age_group = case_when(
age < 40 ~ "青年",
age < 60 ~ "中年",
TRUE ~ "老年"
)
) |>
group_by(diagnosis, age_group) |>
summarise(
n = n(),
mean_survival = mean(survival_months, na.rm = TRUE)
)
# 可视化
ggplot(clinical_summary, aes(x = age_group, y = mean_survival, fill = diagnosis)) +
geom_bar(stat = "identity", position = "dodge") +
labs(title = "不同诊断组的平均生存时间") +
theme_bw()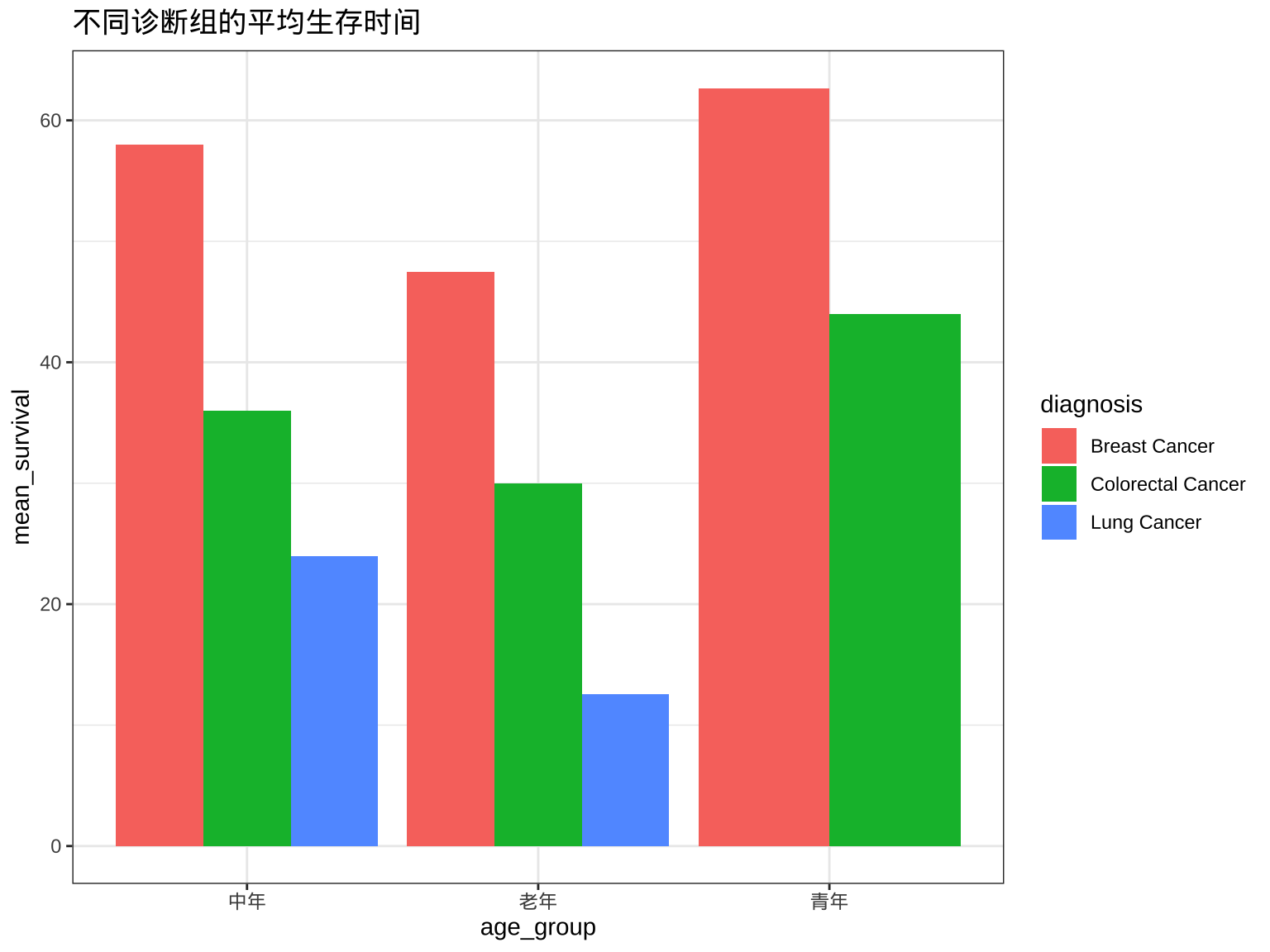
| 概念 | 要点 |
|---|---|
| tidyverse | 统一的数据科学生态 |
| dplyr | 五动词:filter/select/mutate/summarise/arrange |
| 管道操作 | |> 或 |> 连接操作 |
| ggplot2 | 图层语法,aes映射 |
下节预告:R Markdown基础